Anusandhan
2024
Overview
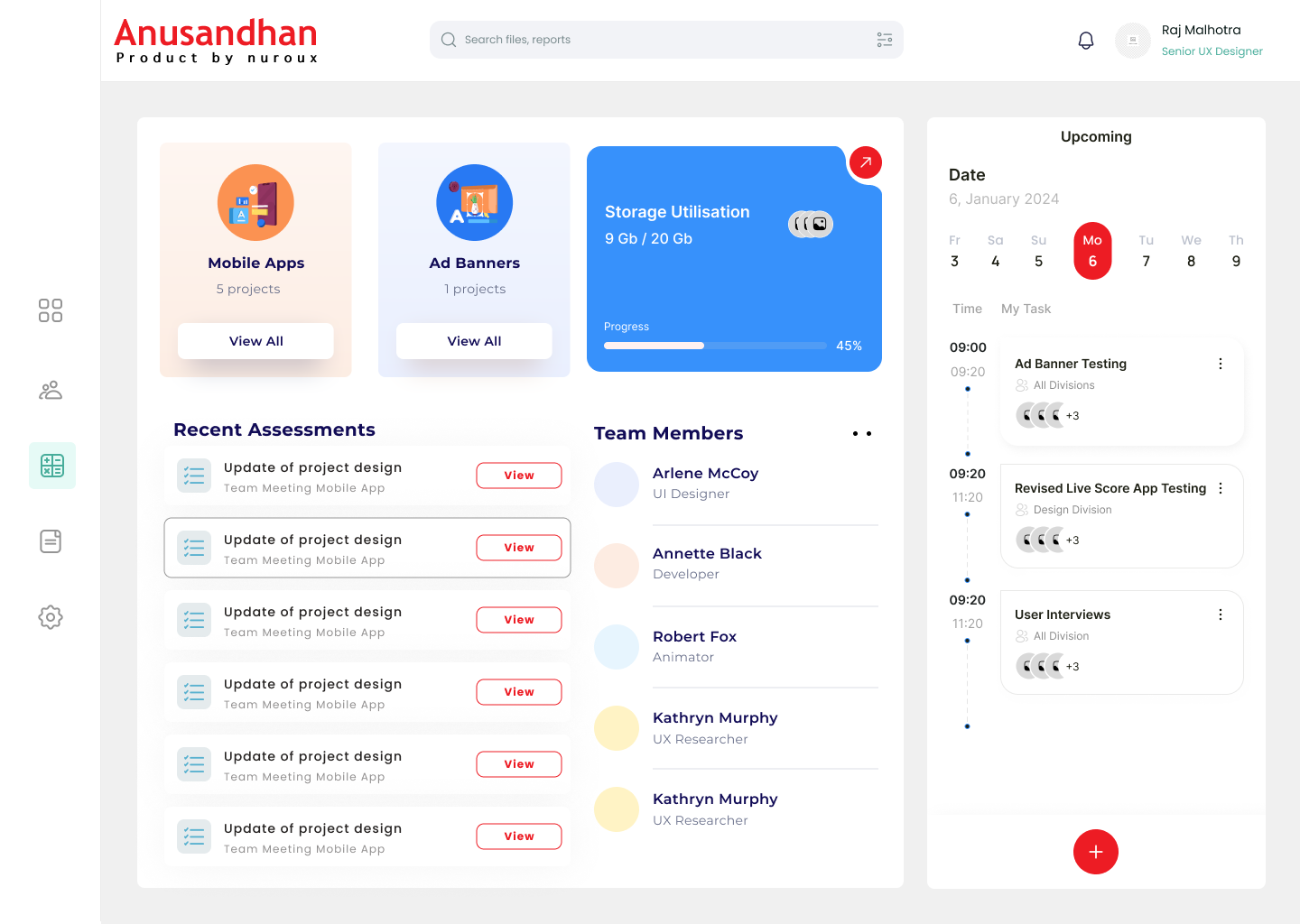
Anusandhan is a sophisticated Flask-based backend system that combines speech recognition, natural language processing, and semantic analysis capabilities. The platform provides a comprehensive suite of APIs for converting speech to text, analyzing textual content, generating visualizations, and managing user authentication. The system implements advanced text processing features including sentiment analysis, word frequency analysis, and semantic relationship visualization.
Background
The project addresses the complex challenge of creating an integrated platform for speech-to-text conversion and advanced text analysis. The technical challenge wasn't just converting audio to text, but doing so reliably while providing sophisticated analysis tools including semantic relationships, sentiment analysis, and data visualization. The system needed to handle: Large audio file processing with chunking mechanisms, Real-time speech-to-text conversion, Complex text analysis and visualization, Secure user authentication, and Scalable data storage.
Architecture
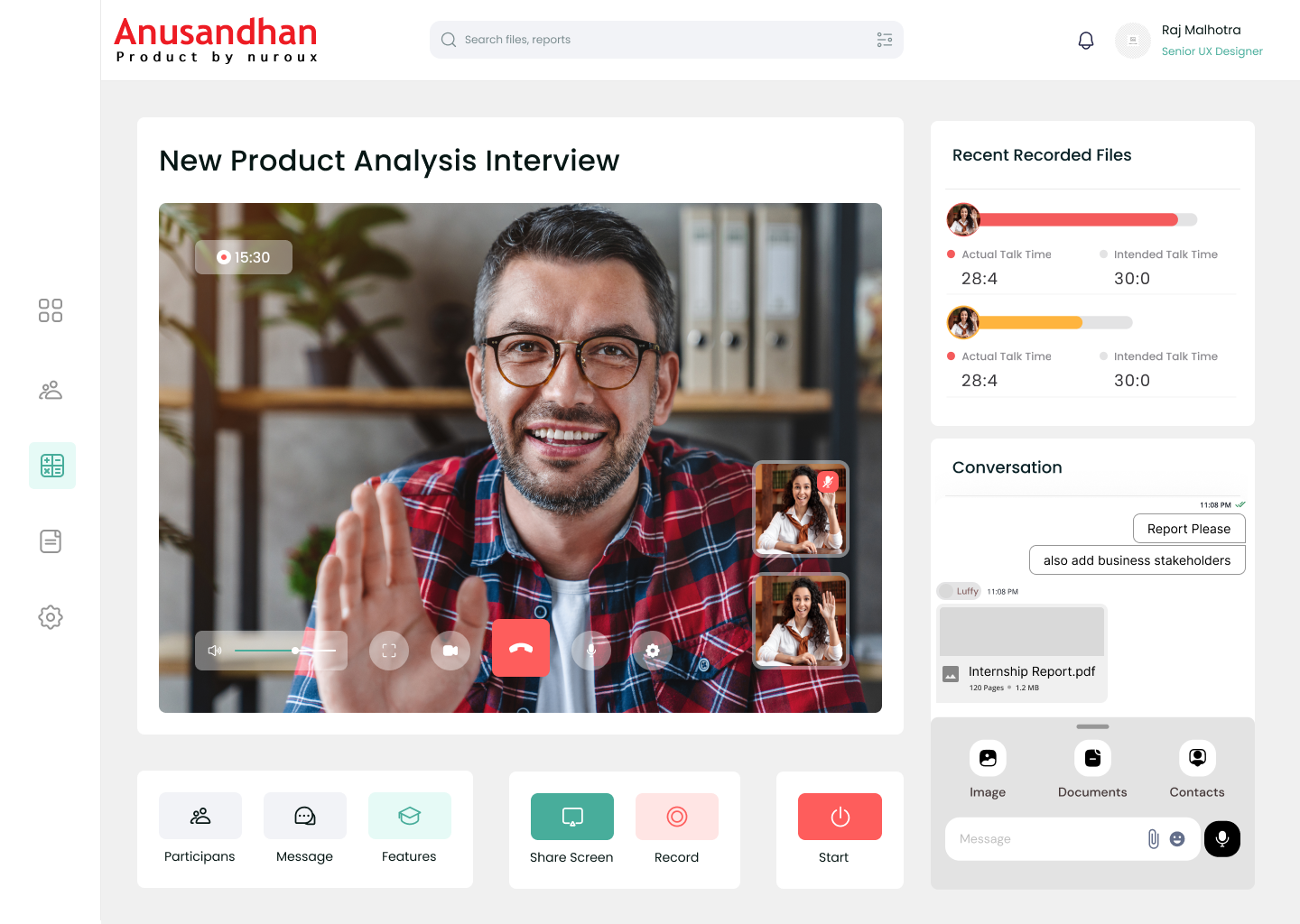
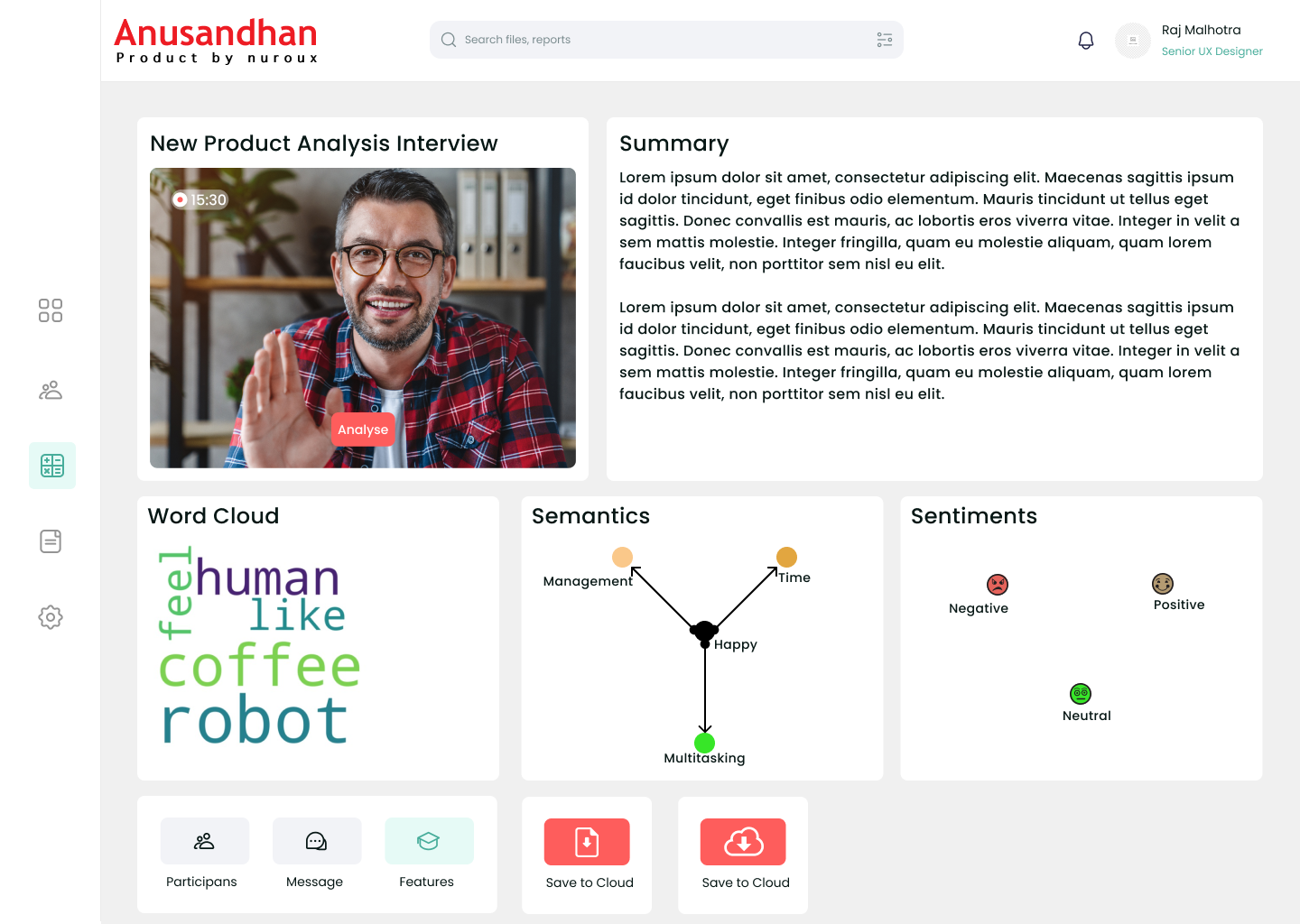
Core Components: API Gateway (api_gateway.py) - Central routing and CORS handling, Integration of all service blueprints, Request/response management. Speech Processing (wav2string.py) - WebM to WAV conversion using FFmpeg, Audio chunking for efficient processing, Google Speech Recognition integration, MongoDB GridFS storage for audio chunks. Text Analysis (backend.py) - Natural Language Processing using NLTK, Word frequency analysis, Sentiment analysis using VADER, Data visualization with matplotlib and WordCloud, Text summarization using LSA. Semantic Analysis (semantics.py) - Word relationship analysis, Network graph generation, POS tagging and stopword removal, Visual representation of semantic connections. Authentication System (auth.py, auth_service.py) - Secure user registration and login, Password hashing with bcrypt, MongoDB user management. Data Storage: MongoDB for user data, processed audio, and analysis results, GridFS implementation for large file storage, Efficient document-based schema design.
Challenges
Audio Processing Complexity - Handling large audio files efficiently, Implementing reliable chunking mechanisms, Managing multiple audio formats, Ensuring accurate speech-to-text conversion.
Text Analysis Performance - Processing large text datasets, Generating meaningful visualizations, Implementing efficient semantic analysis, Balancing accuracy and processing speed.
System Integration - Coordinating multiple services, Managing cross-origin requests, Handling concurrent processing, Ensuring data consistency.
Results & Takeaways
Successfully created a comprehensive platform that seamlessly integrates speech recognition, text analysis, and visualization capabilities. The system handles large-scale audio processing with efficient chunking mechanisms while maintaining high accuracy in speech-to-text conversion.
Implemented advanced NLP features including sentiment analysis, semantic relationship mapping, and automated text summarization. The platform provides actionable insights through intuitive visualizations including word clouds, frequency charts, and network graphs.
The modular architecture enables easy service integration and scaling, while the secure authentication system ensures data privacy. The MongoDB GridFS implementation provides efficient storage and retrieval of large audio files and analysis results.
Timeline
2024
Tools
- Flask
- Google Speech Recognition
- NLTK
- VADER
- MongoDB
- GridFS
- FFmpeg
Technologies
- Python
- Flask
- MongoDB
- GridFS
- Natural Language Processing
- Speech Recognition
- NLTK
- VADER
- Matplotlib
- WordCloud
- Bcrypt